Mysql(8)orderby
Contents
orderby –16
全字段排序
1 | CREATE TABLE `t` ( |
假设要查询杭州市所有人的名字,并且按照姓名排序返回前1000个人的姓名和年龄。
SQL十分清晰,可以这么写select city,name,age from t where city='杭州' order by name limit 1000
为了避免全表扫描,需要在city字段加上索引。添加后,使用explain命令查看执行情况

Extra 这个字段中的“Using filesort”表示的就是需要排序,MySQL 会给每个线程分配一 块内存用于排序,称为 sort_buffer。
先来看city索引的示意图。
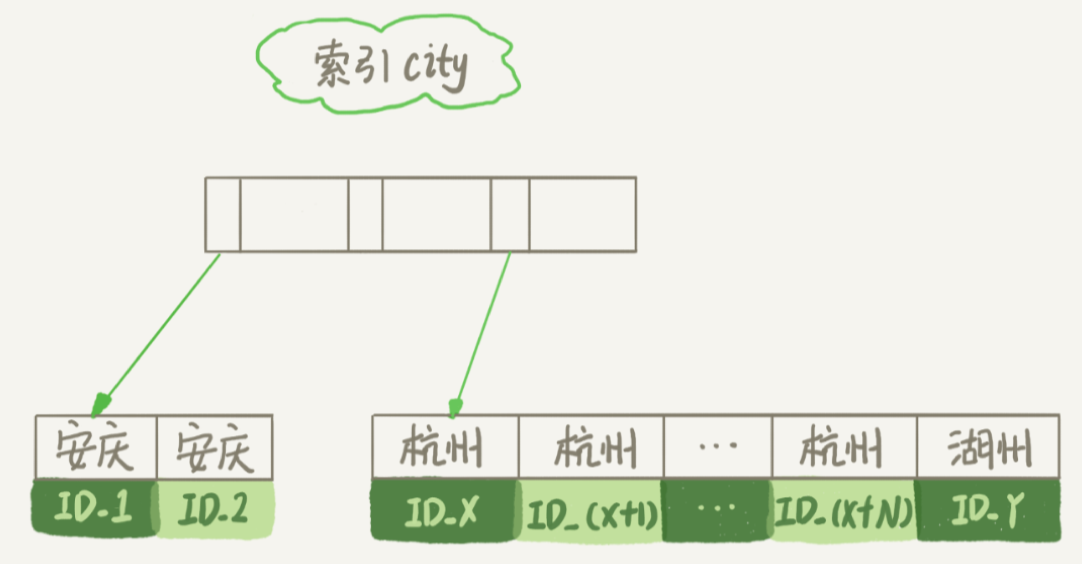
图中可以看到,满足 city=’杭州’条件的行,是从 ID_X 到 ID_(X+N) 的这些记录。
通常情况下,这个语句执行流程如下所示 :
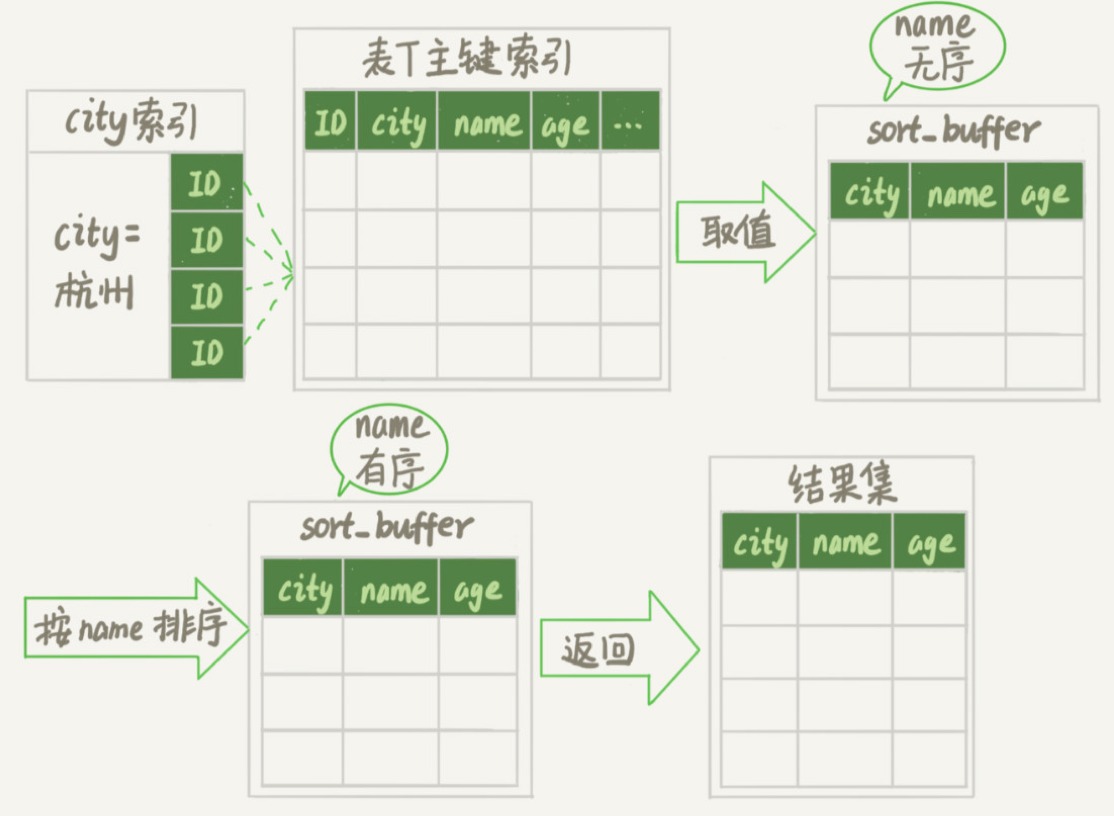
初始化 sort_buffer,确定放入 name、city、age 这三个字段;
从索引 city 找到第一个满足 city=’杭州’条件的主键 id,也就是图中的 ID_X;
到主键 id 索引取出整行,取 name、city、age 三个字段的值,存入 sort_buffer 中;
从索引 city 取下一个记录的主键 id;
重复步骤 3、4 直到 city 的值不满足查询条件为止,对应的主键 id 也就是图中的 ID_Y;
对 sort_buffer 中的数据按照字段 name 做快速排序;
按照排序结果取前 1000 行返回给客户端。
暂且把这个排序过程,称为全字段排序,执行流程的示意图如下所示。
按name 排序的动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数sort_buffer_size。
sort_buffer_size,就是 MySQL 为排序开辟的内存(sort_buffer)的大小。如果要排序的 数据量小于 sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不 下,则不得不利用磁盘临时文件辅助排序。
rowid 排序
上面的算法过程中,只对原表的数据读了一遍,剩下的操作都是在sort_buffer和临时文件中执行的,但这个算法有一个问题,就是如果查询要返回的字段很多的话,那么 sort_buffer 里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个 临时文件,排序的性能会很差。
所以,如果MYSQL认为排序的单行长度太大会怎么做
修改参数max_length_for_sort_data=16,max_length_for_sort_data,是 MySQL 中专门控制用于排序的行数据的长度的一个参 数。它的意思是,如果单行的长度超过这个值,MySQL 就认为单行太大,要换一个算法。
city、name、age 这三个字段的定义总长度是 36,把 max_length_for_sort_data 设置 为 16,再来看看计算过程有什么改变。
新的算法放入 sort_buffer 的字段,只有要排序的列(即 name 字段)和主键 id。
但这时,排序的结果就因为少了 city 和 age 字段的值,不能直接返回了,整个执行流程就 变成如下所示的样子:
- 初始化 sort_buffer,确定放入两个字段,即 name 和 id;
- 从索引 city 找到第一个满足 city=’杭州’条件的主键 id,也就是图中的 ID_X;
- 到主键 id 索引取出整行,取 name、id 这两个字段,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;
- 重复步骤 3、4 直到不满足 city=’杭州’条件为止,也就是图中的 ID_Y;
- 对 sort_buffer 中的数据按照字段 name 进行排序;
- 遍历排序结果,取前 1000 行,并按照 id 的值回到原表中取出 city、name 和 age 三个 字段返回给客户端。
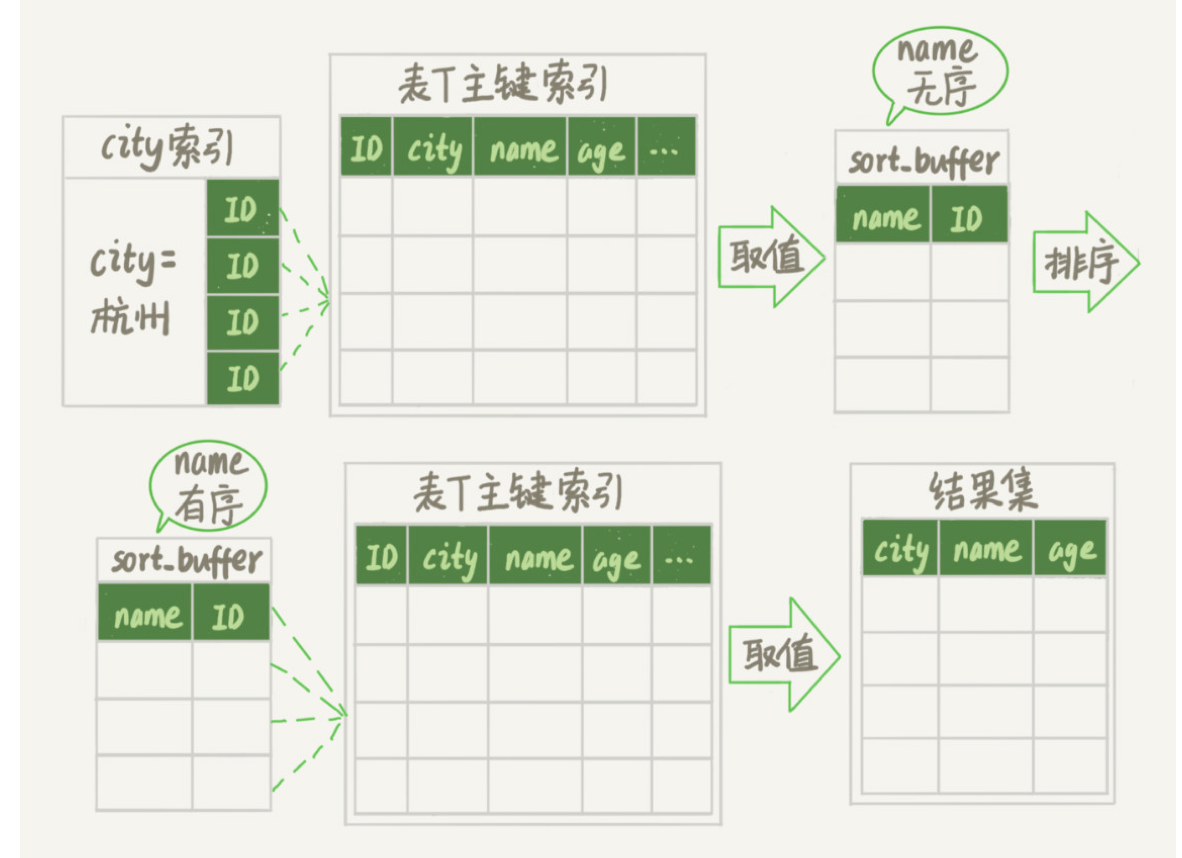
对比全字段排序流程图会发现,rowid 排序多访问了一次表 t 的主键索引.
对比
如果 MySQL 实在是担心排序内存太小,会影响排序效率,才会采用 rowid 排序算法,这 样排序过程中一次可以排序更多行,但是需要再回到原表去取数据。
如果 MySQL 认为内存足够大,会优先选择全字段排序,把需要的字段都放到 sort_buffer 中,这样排序后就会直接从内存里面返回查询结果了,不用再回到原表去取数据。
这也就体现了 MySQL 的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访 问。
Author: corn1ng
Link: https://corn1ng.github.io/2019/10/05/新版Mysql/Mysql(8)orderby/
License: 知识共享署名-非商业性使用 4.0 国际许可协议