ElasticSearch 入门总结
Contents
ElasticSearch 官网入门总结
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene基础之上。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库–无论是开源还是私有。
数据的输入输出
索引文档
通过使用index API,文档可以被索引。
- 使用自定义的ID
如果你的文档有一个自然的标识符 (例如,一个 user_account 字段或其他标识文档的值),你应该使用如下方式的 index API 并提供你自己 _id :
1 | PUT /{index}/{type}/{id} |
- 自增ID
如果你的数据没有自然的 ID, Elasticsearch 可以帮我们自动生成 ID 。 请求的结构调整为: 不再使用 PUT 谓词(“使用这个 URL 存储这个文档”), 而是使用 POST 谓词(“存储文档在这个 URL 命名空间下”)。现在该 URL 只需包含 _index 和 _type 。
1 | POST /website/blog/ |
取回一个文档
为了从 Elasticsearch 中检索出文档,我们仍然使用相同的 _index , _type , 和 _id ,但是 HTTP 谓词更改为 GET 。
1 | GET /website/blog/123?pretty |
返回文档的一部分
默认情况下, GET 请求会返回整个文档,这个文档正如存储在 _source 字段中的一样。但是也许你只对其中的 title 字段感兴趣。单个字段能用 _source 参数请求得到,多个字段也能使用逗号分隔的列表来指定。
1 | GET /website/blog/123?_source=title,text |
检查文档是否存在
如果只想检查一个文档是否存在–根本不想关心内容—那么用 HEAD 方法来代替 GET 方法。 HEAD 请求没有返回体,只返回一个 HTTP 请求报头:
1 | curl -i -XHEAD http://localhost:9200/website/blog/123 |
如果文档存在, Elasticsearch 将返回一个 200 ok 的状态码:
1 | HTTP/1.1 200 OK |
若文档不存在, Elasticsearch 将返回一个 404 Not Found 的状态码:
1 | curl -i -XHEAD http://localhost:9200/website/blog/124 |
更新整个文档
同样使用PUT 即可。
1 | PUT /website/blog/123 |
在响应体中,我们能看到 Elasticsearch 已经增加了 _version 字段值:
1 | { |
在内部,Elasticsearch 已将旧文档标记为已删除,并增加一个全新的文档。 尽管你不能再对旧版本的文档进行访问,但它并不会立即消失。
创建新文档
当我们索引一个文档,怎么确认我们正在创建一个完全新的文档,而不是覆盖现有的呢? _index 、 _type 和 _id 的组合可以唯一标识一个文档。所以,确保创建一个新文档的最简单办法是,使用索引请求的 POST 形式让 Elasticsearch 自动生成唯一 _id :
删除文档
1 | DELETE /website/blog/123 |
文档的部分更新
使用update API 还可以部分更新文档。文档是不可变的:他们不能被修改,只能被替换。 update API 必须遵循同样的规则。 从外部来看,我们在一个文档的某个位置进行部分更新。然而在内部, update API 简单使用与之前描述相同的 检索-修改-重建索引 的处理过程。 区别在于这个过程发生在分片内部,这样就避免了多次请求的网络开销。通过减少检索和重建索引步骤之间的时间,我们也减少了其他进程的变更带来冲突的可能性。
update 请求最简单的一种形式是接收文档的一部分作为 doc 的参数, 它只是与现有的文档进行合并。对象被合并到一起,覆盖现有的字段,增加新的字段。 例如,我们增加字段 tags 和 views 到我们的博客文章。
1 | POST /website/blog/1/_update |
取回多个文档
如果你需要从 Elasticsearch 检索很多文档,那么使用 multi-get 或者 mget API 来将这些检索请求放在一个请求中,将比逐个文档请求更快地检索到全部文档。
mget API 要求有一个 docs 数组作为参数,每个元素包含需要检索文档的元数据, 包括 _index 、 _type 和 _id 。如果你想检索一个或者多个特定的字段,那么你可以通过 _source 参数来指定这些字段的名字:
1 | GET /_mget |
搜索
搜索(search) 可以做到:
- 在类似于
gender或者age这样的字段 上使用结构化查询,join_date这样的字段上使用排序,就像SQL的结构化查询一样。 - 全文检索,找出所有匹配关键字的文档并按照相关性(relevance) 排序后返回结果。
- 以上二者兼而有之。
很多搜索都是开箱即用的,为了充分挖掘 Elasticsearch 的潜力,需要理解以下三个概念:
映射(Mapping)
描述数据在每个字段内如何存储
分析(Analysis)
全文是如何处理使之可以被搜索的
领域特定查询语言(Query DSL)
Elasticsearch 中强大灵活的查询语言
空搜索
最基础的形式是没有指定任何查询的空搜索 ,它简单地返回集群中所有索引下的所有文档:
1 | GET /search |
返回结果中最重要的部分是hits,它包含total字段来表示匹配到的文档总数,并且一个hits数组包含所查询结果的前十个文档。在 hits 数组中每个结果包含文档的 _index 、 _type 、 _id ,加上 _source 字段。这意味着我们可以直接从返回的搜索结果中使用整个文档。每个结果还有一个 _score ,它衡量了文档与查询的匹配程度。默认情况下,首先返回最相关的文档结果,就是说,返回的文档是按照 _score 降序排列的。
took字段告诉执行整个搜索请求耗费了多少毫秒。shards部分告诉我们在查询中参与分片的总数,以及这些分片成功了多少失败了多少。timed_out 值告诉查询是否超时。
多索引 多类型
经常的情况下,在一个或多个特殊的索引并且在一个或者多个特殊的类型中进行搜索。可以通过在URL中指定特殊的索引和类型达到这种效果,如下所示:
1 | /_search |
分页
Elasticsearch 接受 from 和 size 参数:
size显示应该返回的结果数量,默认是 10 from显示应该跳过的初始结果数量,默认是 0
如果每页展示 5 条结果,可以用下面方式请求得到 1 到 3 页的结果:
1 | GET /_search?size=5 |
映射和分析
精确值&全文
Elasticsearch中的数据可以概括的分为两类:精确值和全文。
精确值 如它们听起来那样精确。例如日期或者用户 ID,但字符串也可以表示精确值,例如用户名或邮箱地址。对于精确值来讲,Foo 和 foo 是不同的,2014 和 2014-09-15 也是不同的。
全文 是指文本数据(通常以人类容易识别的语言书写),例如一个推文的内容或一封邮件的内容。
我们很少对全文类型的域做精确匹配。相反,我们希望在文本类型的域中搜索。不仅如此,我们还希望搜索能够理解我们的 意图 :例如搜索UK 也会返回包含United Kindom 的文档等。
这需要分析器的帮助。
分析与分析器
分析 包含下面的过程:
- 首先,将一块文本分成适合于倒排索引的独立的 词条 ,
- 之后,将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall
分析器执行上面的工作。 分析器 实际上是将三个功能封装到了一个包里:
字符过滤器
首先,字符串按顺序通过每个 字符过滤器 。他们的任务是在分词前整理字符串。一个字符过滤器可以用来去掉HTML,或者将
&转化成and。分词器
其次,字符串被 分词器 分为单个的词条。一个简单的分词器遇到空格和标点的时候,可能会将文本拆分成词条。
Token 过滤器
最后,词条按顺序通过每个 token 过滤器 。这个过程可能会改变词条(例如,小写化
Quick),删除词条(例如, 像a,and,the等无用词),或者增加词条(例如,像jump和leap这种同义词)。
什么时候使用分析器???
当我们 索引 一个文档,它的全文域被分析成词条以用来创建倒排索引。 但是,当我们在全文域 搜索 的时候,我们需要将查询字符串通过 相同的分析过程 ,以保证我们搜索的词条格式与索引中的词条格式一致。
全文查询,理解每个域是如何定义的,因此它们可以做正确的事:
- 当你查询一个 全文 域时, 会对查询字符串应用相同的分析器,以产生正确的搜索词条列表。
- 当你查询一个 精确值 域时,不会分析查询字符串,而是搜索你指定的精确值。
https://www.elastic.co/guide/cn/elasticsearch/guide/current/analysis-intro.html
映射
为了能够将时间域视为时间,数字域视为数字,字符串域视为全文或精确值字符串, Elasticsearch 需要知道每个域中数据的类型。这个信息包含在映射中。
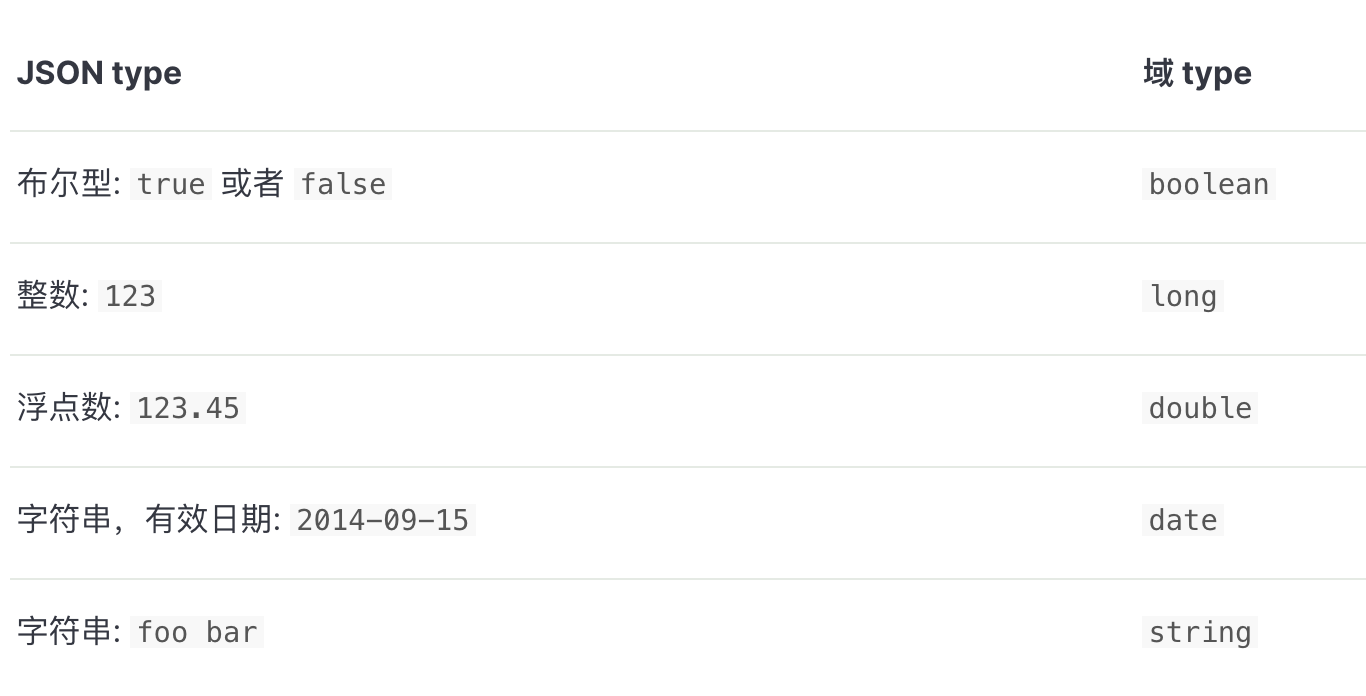
Elasticsearch 支持 如下简单域类型:
- 字符串:
string - 整数 :
byte,short,integer,long - 浮点数:
float,double - 布尔型:
boolean - 日期:
date
当你索引一个包含新域的文档–之前未曾出现– Elasticsearch 会使用 动态映射 ,通过JSON中基本数据类型,尝试猜测域类型,使用如下规则.
通过 /_mapping ,我们可以查看 Elasticsearch 在一个或多个索引中的一个或多个类型的映射 。
1 | //取得索引 gb 中类型 tweet 的映射 |
自定义域映射
尽管在很多情况下基本域数据类型 已经够用,但你经常需要为单独域自定义映射 ,特别是字符串域。自定义映射允许你执行下面的操作:
- 全文字符串域和精确值字符串域的区别
- 使用特定语言分析器
- 优化域以适应部分匹配
- 指定自定义数据格式
- 还有更多
域最重要的属性是 type 。对于不是 string 的域,一般只需要设置 type 。
1 | { |
默认, string 类型域会被认为包含全文。就是说,它们的值在索引前,会通过 一个分析器,针对于这个域的查询在搜索前也会经过一个分析器。
string 域映射的两个最重要 属性是 index 和 analyzer 。
index
index 属性控制怎样索引字符串。它可以是下面三个值:
analyzed首先分析字符串,然后索引它。换句话说,以全文索引这个域。
not_analyzed索引这个域,所以它能够被搜索,但索引的是精确值。不会对它进行分析。
no不索引这个域。这个域不会被搜索到。
string 域 index 属性默认是 analyzed 。如果我们想映射这个字段为一个精确值,我们需要设置它为 not_analyzed :
请求体查询
查询表达式
查询表达式(Query DSL)是一种非常灵活又富有表现力的 查询语言。 Elasticsearch 使用它可以以简单的 JSON 接口来展现 Lucene 功能的绝大部分。在应用中,应该用它来编写查询语句。它可以使你的查询语句更灵活、更精确、易读和易调试。
要使用这种查询表达式,只需将查询语句传递给 query 参数:
1 | GET /_search |
查询语句的结构
一个查询语句的典型结构:
1 | { |
如果是针对某个字段,那么它的结构如下:
1 | { |
查询语句(Query clauses) 就像一些简单的组合块 ,这些组合块可以彼此之间合并组成更复杂的查询。这些语句可以是如下形式:
- 叶子语句(Leaf clauses) (就像
match语句) 被用于将查询字符串和一个字段(或者多个字段)对比。 - 复合(Compound) 语句 主要用于 合并其它查询语句。 比如,一个
bool语句 允许在你需要的时候组合其它语句,无论是must匹配、must_not匹配还是should匹配,同时它可以包含不评分的过滤器(filters) 。
1 | { |
查询与过滤
Elasticsearch 使用的查询语言(DSL) 拥有一套查询组件,这些组件可以以无限组合的方式进行搭配。这套组件可以在以下两种情况下使用:过滤情况(filtering context)和查询情况(query context)。
当使用于 过滤情况 时,查询被设置成一个“不评分”或者“过滤”查询。即,这个查询只是简单的问一个问题:“这篇文档是否匹配?”。回答也是非常的简单,yes 或者 no ,二者必居其一。
当使用于 查询情况 时,查询就变成了一个“评分”的查询。和不评分的查询类似,也要去判断这个文档是否匹配,同时它还需要判断这个文档匹配的有_多好_(匹配程度如何)。 此查询的典型用法是用于查找以下文档。
- 查找与
full text search这个词语最佳匹配的文档 - 包含
run这个词,也能匹配runs、running、jog或者sprint - 包含
quick、brown和fox这几个词 — 词之间离的越近,文档相关性越高 - 标有
lucene、search或者java标签 — 标签越多,相关性越高
一个评分查询计算每一个文档与此查询的 相关程度,同时将这个相关程度分配给表示相关性的字段 _score,并且按照相关性对匹配到的文档进行排序。这种相关性的概念是非常适合全文搜索的情况,因为全文搜索几乎没有完全 “正确” 的答案。
在性能方面,过滤查询要比评分查询快的多,同时,评分查询还不缓存。因此过滤(filtering)的目标是减少那些需要通过评分查询(scoring queries)进行检查的文档。
通常的规则是,使用 查询(query)语句来进行 全文 搜索或者其它任何需要影响 相关性得分 的搜索。除此以外的情况都使用过滤(filters)。
最重要的查询
- match_all
match_all 查询简单的匹配所有文档。在没有指定查询方式时,它是默认的查询:
1 | { "match_all": {}} |
- match
无论你在任何字段上进行的是全文搜索还是精确查询,match 查询是你可用的标准查询。
如果你在一个全文字段上使用 match 查询,在执行查询前,它将用正确的分析器去分析查询字符串:
1 | { "match": { "tweet": "About Search" }} |
如果在一个精确值的字段上使用它, 例如数字、日期、布尔或者一个 not_analyzed 字符串字段,那么它将会精确匹配给定的值。
1 | { "match": { "age": 26 }} |
- multi_match
multi_match 查询可以在多个字段上执行相同的 match 查询:
1 | { |
- range
range 查询找出那些落在指定区间内的数字或者时间。
1 | { |
- term
term 查询被用于精确值 匹配,这些精确值可能是数字、时间、布尔或者那些 not_analyzed 的字符串。term 查询对于输入的文本不分析 ,所以它将给定的值进行精确查询。
1 | { "term": { "age": 26 }} |
- terms
terms 查询和 term 查询一样,但它允许你指定多值进行匹配。如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件:
1 | { "terms": { "tag": [ "search", "full_text", "nosql" ] }} |
- Exists 和missing
exists 查询和 missing 查询被用于查找那些指定字段中有值 (exists) 或无值 (missing) 的文档。这与SQL中的 IS_NULL (missing) 和 NOT IS_NULL (exists) 在本质上具有共性。
短语搜索
找出一个属性中的独立单词是没有问题的,但有时候想要精确匹配一系列单词或者短语 。 比如, 我们想执行这样一个查询,仅匹配同时包含 “rock” 和 “climbing” ,并且 二者以短语 “rock climbing” 的形式紧挨着的雇员记录。
为此对 match 查询稍作调整,使用一个叫做 match_phrase 的查询。返回的就只有同时满足rock 和climbing 连着的记录了。
组合多查询
现实的查询需要在多个字段上查询多种多样的文本,并且根据一系列的标准来过滤。为了构建类似的高级查询,需要一种能够将多查询组合成单一查询的查询方法。这就是bool查询。这种查询将多查询组合在一起,成为用户自己想要的布尔查询。它接收下面的参数:
- must 文档必须匹配这些条件才能被包含进来。
- must_not 文档必须不匹配这些条件才能被包含进来。
- should 如果满足这些语句中的任意语句,将增加_score, 否则,无任何影响,主要用于修正每个文档的相关性得分。
- filter 必须匹配,但它以不评分,过滤模式来进行,这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
1 | 如果没有 must 语句,那么至少需要能够匹配其中的一条 should 语句。但,如果存在至少一条 must 语句,则对 should 语句的匹配没有要求。 |
1 | { |
如果你需要通过多个不同的标准来过滤你的文档,bool 查询本身也可以被用做不评分的查询。简单地将它放置到 filter 语句中并在内部构建布尔逻辑。
1 | { |
constant_score 查询
尽管没有 bool 查询使用这么频繁,constant_score 查询也是一种有用的查询工具。它将一个不变的常量评分应用于所有匹配的文档。它被经常用于只需要执行一个 filter 而没有其它查询(例如,评分查询)的情况下。
可以使用它来取代只有 filter 语句的 bool 查询。在性能上是完全相同的,但对于提高查询简洁性和清晰度有很大帮助。
1 | { |
验证查询
查询可以写的非常复杂,通过validate-query API可以用来验证查询是否合法。
1 | GET /gb/tweet/_validate/query |
为了找出 查询不合法的原因,可以将 explain 参数 加到查询字符串中:
1 | GET /gb/tweet/_validate/query?explain |
排序
为了按照相关性来排序,需要将相关性表示为一个数值,在ES中,相关性得分由一个浮点数进行表示,并在搜索结果中通过_score参数返回,默认排序是_score降序。
按照字段的值排序
通过时间来对 tweets 进行排序是有意义的,最新的 tweets 排在最前。 我们可以使用 sort 参数进行实现。
1 | GET /_search |
多级排序
假定我们想要结合使用 date 和 _score 进行查询,并且匹配的结果首先按照日期排序,然后按照相关性排序。
1 | GET /_search |
排序条件的顺序是很重要的。结果首先按第一个条件排序,仅当结果集的第一个 sort 值完全相同时才会按照第二个条件进行排序,以此类推。
多级排序并不一定包含 _score 。可以根据一些不同的字段进行排序, 如地理距离或是脚本计算的特定值。
多值字段的排序
一种情形是字段有多个值的排序, 需要记住这些值并没有固有的顺序;一个多值的字段仅仅是多个值的包装,这时应该选择哪个进行排序呢?
对于数字或日期,你可以将多值字段减为单值,这可以通过使用 min 、 max 、 avg 或是 sum 排序模式 。 例如你可以按照每个 date 字段中的最早日期进行排序,通过以下方法:
1 | "sort": { |
索引管理
之前创建的索引都是默认的配置,新的字段通过动态映射的方式被添加到类型映射,现在我们需要对这个建立索引的过程做更多的控制,想要确保这个索引有数量适中的主分片,并且在我们索引任何数据 之前 ,分析器和映射已经被建立好。
为了达到这个目的,需要手动创建索引,在请求体里面传入设置或类型映射,如下所示:
1 | PUT /my_index |
索引设置
通过修改配置来自定义索引行为。
下面是两个最重要的设置:
number_of_shards每个索引的主分片数,默认值是
5。这个配置在索引创建后不能修改。number_of_replicas每个主分片的副本数,默认值是
1。对于活动的索引库,这个配置可以随时修改。
例如创建一个只有一个主分片,没有副本的小索引。
1 | PUT /my_temp_index |
配置分析器
第三个重要的索引设置是analysis部分,用来配置已存在的分析器或针对你的索引创建新的自定义分析器。standred分析器是用于全文字段的默认分析器,用于将全文字符串转换为适合搜索的倒排索引。
1 | PUT /spanish_docs |
自定义分析器
1 | PUT /my_index |
类型与映射
类型在ES中表示一类相似的文档,类型由名称和映射组成。映射,就像Schema,描述了文档可能具有的字段或属性,每个字段的数据类型以及Lucene是如何索引和存储这些字段的。
类型可以很好的抽象划分相似但是不相同的数据,但是由于Lucene的处理方式,类型的使用有些限制。
在 Lucene 中,一个文档由一组简单的键值对组成。 每个字段都可以有多个值,但至少要有一个值。 类似的,一个字符串可以通过分析过程转化为多个值。Lucene 不关心这些值是字符串、数字或日期–所有的值都被当做 不透明字节 。
当我们在 Lucene 中索引一个文档时,每个字段的值都被添加到相关字段的倒排索引中。你也可以将未处理的原始数据 存储 起来,以便这些原始数据在之后也可以被检索到。
根对象
映射的最高一层被称为根对象,包含下面几项
- 一个 properties 节点,列出了文档中可能包含的每个字段的映射
- 各种元数据字段,它们都以一个下划线开头,例如
_type、_id和_source - 设置项,控制如何动态处理新的字段,例如
analyzer、dynamic_date_formats和dynamic_templates - 其他设置,可以同时应用在根对象和其他
object类型的字段上,例如enabled、dynamic和include_in_all
属性 属性的三个最重要的设置
- type
字段的数据类型,例如 string 或 date
- index
字段是否应当被当成全文来搜索( analyzed ),或被当成一个准确的值( not_analyzed ),还是完全不可被搜索( no )
- analyzer
确定在索引和搜索时全文字段使用的 analyzer
动态映射
当ES遇到文档中以前未遇到的字段,用动态映射来确定字段的数据类型并自动把新的字段添加到类型映射。
当 Elasticsearch 遇到文档中以前 未遇到的字段,它用 dynamic mapping来确定字段的数据类型并自动把新的字段添加到类型映射。
有时这是想要的行为有时又不希望这样。通常没有人知道以后会有什么新字段加到文档,但是又希望这些字段被自动的索引。也许你只想忽略它们。如果Elasticsearch是作为重要的数据存储,可能就会期望遇到新字段就会抛出异常,这样能及时发现问题。
幸运的是可以用 dynamic 配置来控制这种行为 ,可接受的选项如下:
true动态添加新的字段–缺省
false忽略新的字段
strict如果遇到新字段抛出异常
配置参数 dynamic 可以用在根 object 或任何 object 类型的字段上。你可以将 dynamic 的默认值设置为 strict , 而只在指定的内部对象中开启它, 例如:
1 | PUT /my_index |
1如果遇到新字段,对象my_type 抛出异常
2 内部对象 stash 遇到新字段会动态创建新字段。
使用上述动态映射, 你可以给 stash 对象添加新的可检索的字段:
1 | PUT /my_index/my_type/1 |
但是对根节点对象 my_type 进行同样的操作会失败:
1 | PUT /my_index/my_type/1 |
把 dynamic 设置为 false 一点儿也不会改变 _source 的字段内容。 _source 仍然包含被索引的整个JSON文档。只是新的字段不会被加到映射中也不可搜索。
Author: corn1ng
Link: https://corn1ng.github.io/2019/10/03/ElasticSearch官网入门总结/
License: 知识共享署名-非商业性使用 4.0 国际许可协议