Kafka 分区与压缩算法
kafka 分区与压缩算法(二)
分区
使用kafka生产和消费消息的时候,肯定希望能够将数据均匀的分配到所有服务器上,如何将大数据量的数据分配到kafka的各个broker上,是一个重要的问题。
kafka有主题的概念,在主题下还有若干个分区。也就是说 Kafka 的消息组织方式实际上是三级结构:主题 - 分区 - 消息。主题下的每条消息只会保存在某一个分区中,而不会在多个分区中被保存多份。
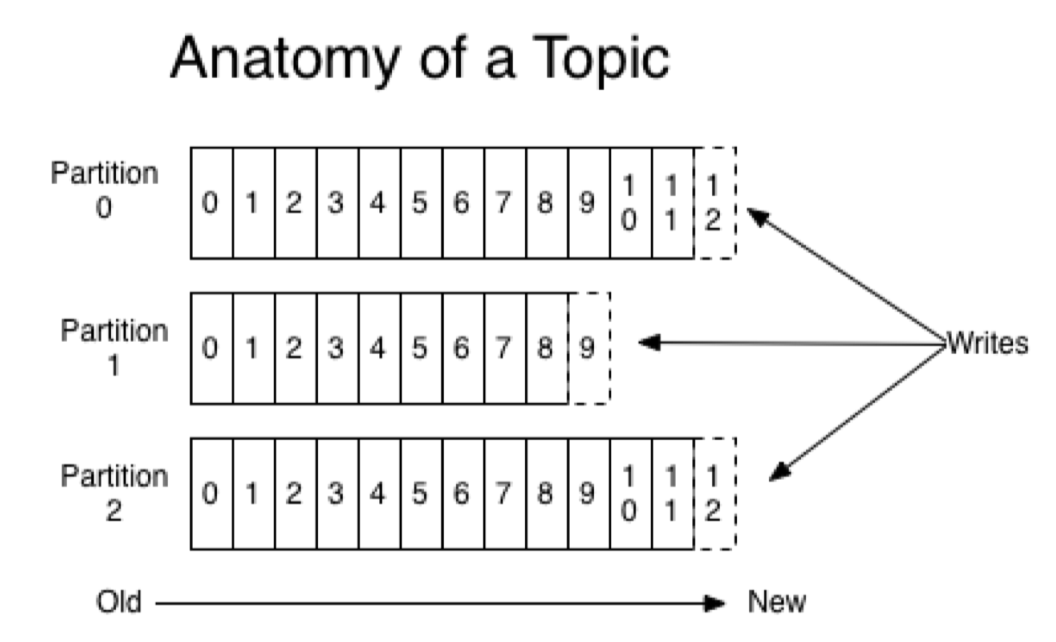
分区的作用就是提供负载均衡的能力,不同的分区能够被放置到不同节点的机器上。而数据的读写操作也都是针对分区这个粒度而进行的, 这样每个节点的机器都能独立地执行各自分区的读写请求处理。
分区策略
所谓分区策略是决 定生产者将消息发送到哪个分区的算法。所谓分区策略是决 定生产者将消息发送到哪个分区的算法。Kafka 为我们提供 了默认的分区策略,同时它也支持自定义分区策略。
如果要自定义分区策略,你需要显式地配置生产者端的参数 partitioner.class。
轮询策略
也称 Round-robin 策略,即顺序分配。比如一个主题下有 3 个分区,那么第一条消息被发送到分区 0,第二条被发送 到分区 1,第三条被发送到分区 2,以此类推。当生产第 4 条消息时又会重新开始,即将其分配到分区 0。轮询策略是 Kafka Java 生产者 API 默认提供的分区策略。
随机策略
也称 Randomness 策略。所谓随机就是我们随意地将消息 放置到任意一个分区上。
按消息键保序策略
Kafka 允许为每条消息定义消息键,简称为 Key。这个 Key 的作用非常大,它可以是一个有着明确业务含义的字符串, 比如客户代码、部门编号或是业务ID 等;也可以用来表征 消息元数据。特别是在 Kafka 不支持时间戳的年代,在一些场景中,工程师们都是直接将消息创建时间封装进 Key 里面的。一旦消息被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面,由于每个分区下 的消息处理都是有顺序的,故这个策略被称为按消息键保序策略。
前面提到的 Kafka 默认分区策略实际上同时实现了两种策 略:如果指定了 Key,那么默认实现按消息键保序策略;如 果没有指定 Key,则使用轮询策略。
生产者压缩算法
压缩时机
kafka中的消息是可以压缩的,目前Kafka 共有两大类消息格式,社区分别称之为 V1 版本和 V2 版本。V2 版本是 Kafka 0.11.0.0 中正式引入的。
不论是哪个版本,Kafka 的消息层次都分为两层:消息集合(message set)以及消息 (message)。一个消息集合中包含若干条日志项(record item),而日志项才是真正封装消息的地方。Kafka 底层的消息日志由一系列消息集合日志项组成。Kafka 通常不会直接操作具体的一条条消息,它总是在消息集合这个层面上进行写入操作。
在 Kafka 中,压缩可能发生在两个地方:生产者端和 Broker 端。
生产者程序中配置 compression.type 参数即表示启用指定类型的压缩算法。
其实 大部分情况下 Broker 从 Producer 端接收到消息后仅仅是原封不动地保存而不会对其进行 任何修改,但这里的“大部分情况”也是要满足一定条件的。有两种例外情况就可能让 Broker 重新压缩消息。
- 情况一:Broker 端指定了和 Producer 端不同的压缩算法。
- Broker 端发生了消息格式转换。(所谓的消息格式转换主要是为了兼容老版本的消费者程序。还记得之前说过的 V1、V2 版 本吧?在一个生产环境中,Kafka 集群中同时保存多种版本的消息格式非常常见。为了兼容 老版本的格式,Broker 端会对新版本消息执行向老版本格式的转换。这个过程中会涉及消 息的解压缩和重新压缩。)
通常来说解压缩发生在消费者程序中,也就是Producer发送压缩消息到broker后,broker原样保存起来,当 Consumer 程序请求这部分消息 时,Broker 依然原样发送出去,当消息到达 Consumer 端后,由 Consumer 自行解压缩 还原成之前的消息。Kafka 会将启用了哪种压缩算法封装进消息集合中,这样当 Consumer 读取 到消息集合时,它自然就知道了这些消息使用的是哪种压缩算法。如果用一句话总结一下压 缩和解压缩,Producer 端压缩、Broker 端保持、Consumer 端解压缩。
压缩算法
Kafka 支持 3 种压缩算法:GZIP、Snappy 和 LZ4。从 2.1.0 开 始,Kafka 正式支持 Zstandard 算法(简写为 zstd)。它是 Facebook 开源的一个压缩算法,能够提供超高的压缩比(compression ratio)。
1 | 看一个压缩算法的优劣,有两个重要的指标:一个指标是压缩比,原先占 100 份空 间的东西经压缩之后变成了占 20 份空间,那么压缩比就是 5,显然压缩比越高越好;另一 个指标就是压缩 / 解压缩吞吐量,比如每秒能压缩或解压缩多少 MB 的数据。同样地,吞 吐量也是越高越好。 |
Author: corn1ng
Link: https://corn1ng.github.io/2019/10/02/kafka/Kafka2 分区与压缩算法/
License: 知识共享署名-非商业性使用 4.0 国际许可协议