Lambda与stream
Contents
行为参数化
可以将这个名词分开拆解,行为+参数化。
行为:即某一段具体的业务代码块,甚至可以简单的理解为,一个函数中{}之中的内容,如
1 | public void saySomething(){ |
参数化就是:将行为作为参数,传递给另一个方法,那么,接受该行为的方法,就可以根据不同的行为参数,进行不同的业务操作。
行为参数化,本质就是让一个方法接受多个不同行为作为参数,并在内部使用它们,从而实现不同行为的能力。
行为参数化,可让代码更好适应不断变化的需求,减轻未来工作量。
Lambda
lambda表达式,是用来实现行为参数化的一个载体,或者称之为工具,它可以很简洁地表示一个行为或者传递代码。这与java中的匿名函数一样。
可以把lambda表达式理解为简洁地表示可传递匿名函数的一种方式:它没有名称,但是又参数列表,函数主体,返回类型,可能还有一个可以抛出的异常列表。这个定义比较广泛,一步步拆分开来解释。
在哪里使用
在使用Lambda表达式之前,需要做两个预先准备:函数式接口、函数描述符。
3.1 函数式接口
定义:只定义了一个抽象方法的接口,但该接口允许有多个默认方法。
例如:
1 | public interface Comparator<T> { |
作用:lambda表达式允许你直接以内联的形式为函数式接口的抽象放阿飞提供实现,并且把整个表达式作为函数式接口的实例(具体来说,是函数式接口一个具体实现的实例)。当然也可以用匿名内部类完成同样的事情,只是显得比较笨拙。
以Runnable接口为例,下面以lambda表达式形式展现的代码是有效的:
1 | Runnable r1 = () -> System.out.println("Hello Java8"); |
3.2 函数描述符
函数式接口的抽象方法的签名基本上就是Lambda表达式的签名,我们称此种抽象方法为函数描述符。例如Runnable接口可以看做一个什么也不接受什么也不返回的函数的签名,因为它只有一个run抽象方法,这个方法什么也不接受,什么也不返回。
所以,Runnable接口的函数描述符就是() -> void,它代表参数列表为空,且返回类型为void的函数。
函数式接口
函数式接口,其实就是只存在一个抽象方法的接口(允许有多个默认方法)。函数描述符,就是函数式接口的抽象方法的签名。
Java API中其实已经有了几个函数式接口,以Java8为例,在java.util.function包中,引入了几个新的函数式接口。主要介绍三种函数式接口:Predicate、Consumer、Function。这三个接口是在Java8中提供的Stream API中应用最为广泛的接口。
1) Predicate
Predicate<T>接口中定义了一个名为test的抽象方法,表示接受一个泛型对象T并返回一个Boolean(函数描述符:(T t) -> Boolean)。下面就是Predicate接口的一个简单示例。
1 |
|
1 | public static <T> List<T> filter(List<T> list, Predicate<T> p) { |
2) Consumer
Consumer<T>接口则定义了一个名为accept的抽象方法,它接受一个泛型T的对象,并没有任何返回(函数描述符:(T t) -> void) 即如果需要访问类型T的对象,并对其执行相应的操作,便可使用该接口。Stream API中的forEach方法,就是利用该接口进行实现的。
1 |
|
下面就是利用Consumer实现一个foreach的小例子:
1 | public static <T> void forEach(List<T> list, Consumer<T> c) { |
3) Function
Function<T, R>接口定义了一个叫做apply的抽象方法,表示它接受一个泛型T的对象,并返回泛型R的对象(函数描述符:(T t) -> R)即Stream API中的map方法就是对Function的一个典型应用的例子。
1 |
|
方法引用
方法引用,可以被看做是仅仅调用特定方法的Lambda表达式的一种快捷写法。换句话说,如果lambda表达式是直接调用一个类中现成的方法时,可以用方法引用代替。
举个例子:
当需要比较促销商品中的促销价格,不使用方法引用,写法如下:
1 | Comparator<PromotionGoods> c1 = (g1, g2) -> g1.getPromotionSalePrice().compareTo(g2.getPromotionSalePrice()); |
观察上述lambda表达式可知,lambda表达式中,只是直接调用了PromotionGoods的getPromotionSalePrice()方法去获取促销商品价格,进而调用compareTo方法进行比较,而没有其他多余的业务逻辑操作。
此时,就可以用方法引用来代替:
1 | Comparator<PromotionGoods> c1 = Comparator.comparing(PromotionGoods::getPromotionSalePrice); |
使用方法引用之后,可以发现,代码具有更好的可读性。
如何使用:当需要使用方法引用时,目标引用和对应的方法名称,用“::”进行分隔。就像上一节的代码 :PromotionGoods::getPromotionSalePrice,其实本质就是Lambda表达式:(PromotionGoods goods) -> goods.getPromotionSalePrice()的快捷写法。
这里需要注意,方法名称,并不需要带上(),因为你并没有实际调用这个方法。
Stream
Java8中提供了一套全新的API:Stream API,这一套API是用来处理集合的方法集,也正是因为有了Stream API,才使得对集合的操作的代码表达比之前更加通俗和简练。
流,是Java API的新成员,它允许我们用声明式的方式处理数据集合,即通过查询语句来表达,而不是去临时实现。就现在来说,你可以把流看成遍历数据集的高级迭代器。此外,流还可以透明地并行处理,你无需编写任何多线程代码。
流操作
中间操作
诸如filter或者sorted等可以连接起来的操作称为中间操作
终端操作
关闭流的操作则称为终端操作
一般而言,使用流一般包括三件事情:
1) 一个数据源(比如集合)来执行一个查询
2) 一个中间操作链,形成一条流的流水线
3) 一个终端操作,执行流水线,并能生成结果。
而流的流水线背后的理念,类似于设计模式中的构建器模式,通过一个调用链来设置一套配置,最后调用build方法获得最终对象。
常见操作
谓词筛选
Streams接口是支持filter方法。这个操作会接受一个谓词(其实就是一个返回boolean的lambda表达式,也可以是一个返回boolean的方法引用)作为参数,并返回一个包含所有符合谓词的元素的流。
1 | List<Dish> vega =menu.stream().filter(Dish::isApple).collect(toList()); //方法应用检查菜是否是苹果做的菜。 |
去重筛选
除了谓词筛选之外,流还支持distinct操作,意思是筛选出一个元素各异的流,即对流进行去重操作(通过流所生成的元素的hashCode和equals方法实现),具体如下所示。
1 | List<Integer> number = Arrays.asList(1, 2, 1, 3, 3, 2, 4); |
分片-截短流
流支持limit(n)方法,该方法会返回一个不超过给定长度n的流,比如筛选出卡路里超过300的头三道菜。
1 | List<Dish> dishes = menu.stream() |
分片-跳过元素
流还支持skip(n)方法,返回从第n+1个元素之后的流。如果流中元素数量不足n,则返回一个空的流。这里需要注意,limit和skip是互补的,比如,下面的例子是跳过卡路里超过300的头两道菜。
1 | List<Dish> dished =menu.stream.filter(d->d.getCalories()>300).skip(2).collect(toList()); |
在讲完流的筛选和切片操作之后,还有一个非常常见的数据处理套路,就是从某些对象中,提取指定的属性,类比sql语句,我可以选择 select * from XXX_TBALE 也可以选择指定的列,如 select id from XXX_TBALE。而Stream API则通过提供map和flatMap方法提供类似的效果。
map
流支持map方法,它会接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映 射成一个新的元素(使用映射一词,是因为它和转换类似,但其中的细微差别在于它是“创建一 个新版本”而不是去“修改”)。例如,下面的代码把方法引用Dish::getName传给了map方法, 来提取流中菜肴的名称:
1 | List<String> dishNames = menu.stream().map(Dish::getName).collect(toList()); |
flatMap
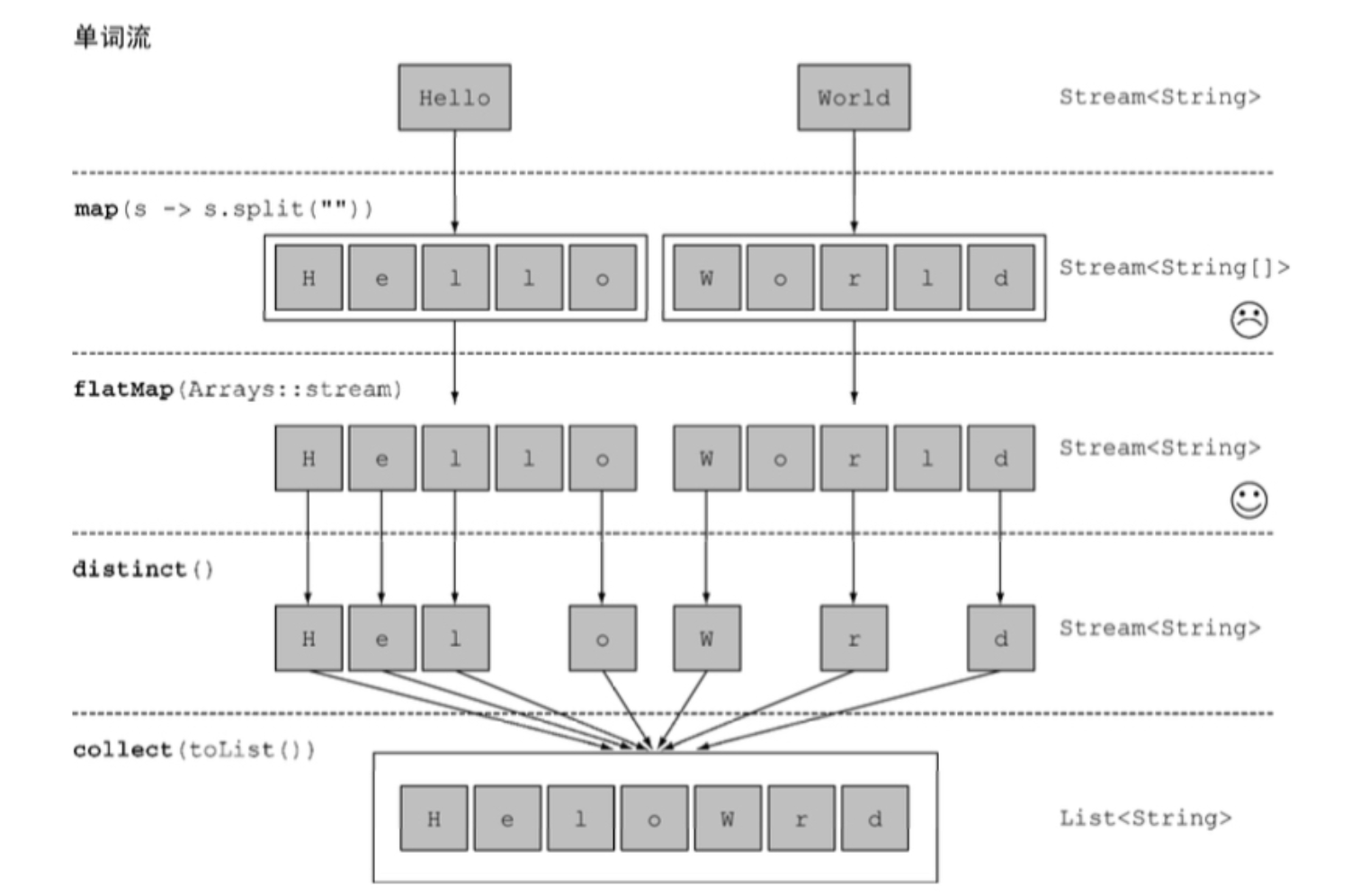
现在我们已经可以通过map操作统计单词(菜名)的长度了,那么现在来了一个新的需求,假设有一张单词表,需要列出单词表里各不相同的字符,比如["Hello","World"],你想要返回列表["H","e","l", "o","W","r","d"]。
此时就可以利用flatMap了:
扁平化流的本质含义,其实就是把多个流合并成一个流,方便后续做统一的操作,以上图为例,就是将Hello和World所生成的两个流,利用flatMap打破屏障,整合成一个流,然后再利用distinct进行整合操作,并实现最终效果。
匹配 -anyMatch
该方法表示,流中是否有一个元素能够匹配给定的谓词。例如:
1 | private static boolean isVegetarianFriendlyMenu(){ |
匹配 -allMatch
该方法表示,流中所有元素是否都匹配给定的谓词。
1 | private static boolean isHealthyMenu(){ |
匹配- noneMatch
该方法表示,流中没有任何元素匹配给定的谓词。
1 | private static boolean isHealthyMenu2(){ |
查找 -findAny
该方法将返回当前流中的任意元素,可以与其他流操作结合使用,比如filter操作。
1 | private static Optional<Dish> findVegetarianDish(){ |
查找 -findFirst
1 | private static Optional<Dish> findFirstVegetarianDish(){ |
规约
归约,则是将流中的元素“收集”起来,收集的方式有很多种,可以将流collect为一个list(collect(toList)),也可以使用reduce操作来进行一些相关计算,比如元素求和和最值计算。
流操作状态
流的操作可以分为有状态和无状态。
诸如map、filter等操作会从输入流中获取每一个元素,并在输出流中得到1个或者0个结果,这种操作是无状态的:他们没有内部状态(假设用户提供的lambda表达式或者方法引用没有内部可变状态)
而诸如reduce、sum、max等操作,需要内部状态来积累,而且,不管流中元素有多少,内部状态都是有界的,此类操作称为有状态-有界操作。
再诸如sort或者distinct等操作一开始都是和map、filter差不多,接受一个流再生成一个流(中间操作),但有一个关键区别,即都需要知道先前的历史且存储要求是无界的,。我们把这些需要知道先前历史的操作称,且存储要求为无界的,称之为有状态-无界操作。
总结
Stream API能够表达复杂的数据处理查询操作:
a) filter、distinct、skip和limit可以对流筛选和切片
b) map和flatMap用于提取流中元素的属性或者转换流中的元素,其中flatMap可以对流进行扁平化处理
c) findFirst、findAny可以查找流中元素。anyMatch、allMatch、noneMatch可以对流中的元素进行谓词匹配。
d) 利用reduce可以将流中所有元素迭代成一个结果。
e) 流操作分为有状态和无状态,filter和map是无状态的,不存储任何状态,reduce则需要存储状态才能计算一个值,而sort、distinct等操作也需要存储状态,因为它们需要把流中的所有元素缓存起来才能返回一个新值。
这里,发现了一个很熟悉的词:map-reduce。没错,这里蕴含的思想,和前几年(包括现在一直都很核心的)大数据处理思想MapReduce是一致的,因为Google用它来进行网络搜索而出名。同时,这种模式有一个很大的优势:非常容易并行化。
Author: corn1ng
Link: https://corn1ng.github.io/2019/09/09/Lambda与Stream/
License: 知识共享署名-非商业性使用 4.0 国际许可协议