Java虚拟机 举例与JIT
Contents
宏观看JVM
先来看一个简单的Java程序
1 | public class Person { |
.java文件通过词法分析器,token流,语法分析器,语法树,语义分析器,注解抽象语法树,字节码生成器等步骤将.java文件变为字节码文件
编译时期—语法糖
语法糖可以看做是编译器实现的一些小把戏,这些小把戏可能会使得效率大提升。
最值得说明的就是泛型,泛型只会在Java源码中存在,编译过后会被替换为原来的原生类型了,这个过程也被称为泛型擦除。
JVM 实现跨平台
.class文件是不能直接运行的,不像C语言(编译cpp后生成的exe是可以直接运行的)
这些.class文件是要交给JVM来解析运行。
class文件和JVM
前面例子中的两个文件都会被直接加载到JVM中吗。并不会
虚拟机规范则是严格规定了有且只有5种情况必须立即对类进行“初始化”(class文件加载到JVM中):
- 创建类的实例(new 的方式)。访问某个类或接口的静态变量,或者对该静态变量赋值,调用类的静态方法
- 反射的方式
- 初始化某个类的子类,则其父类也会被初始化
- Java虚拟机启动时被标明为启动类的类,直接使用java.exe命令来运行某个主类(包含main方法的那个类)
- 当使用JDK1.7的动态语言支持时(….)
所以说
Java类的加载是动态的,它并不会一次性将所有类全部加载后再运行,而是保证程序运行的基础类(像是基类)完全加载到jvm中,至于其他类,则在需要的时候才加载。这当然就是为了节省内存开销。
如何将类加载到JVM
class 文件通过类的加载器装载到jvm中的。
默认三种类加载器。
各个加载器的工作责任:
- 1)Bootstrap ClassLoader:负责加载$JAVA_HOME中jre/lib/rt.jar里所有的class,由C++实现,不是ClassLoader子类
- 2)Extension ClassLoader:负责加载java平台中扩展功能的一些jar包,包括$JAVA_HOME中jre/lib/*.jar或-Djava.ext.dirs指定目录下的jar包
- 3)App ClassLoader:负责记载classpath中指定的jar包及目录中class
类加载器在成功加载某个类之后,会把得到的java.lang.Class 类的实例缓存起来,下次再请求加载该类加载的时候,类加载器会直接使用缓存的类的实例,而不会尝试再次加载
类加载的详细过程
加载器加载到jvm中,接下来其实又分了好几个步骤:
- 加载,查找并加载类的二进制数据,在Java堆中也创建一个java.lang.Class类的对象。
- 连接,连接又包含三块内容:验证、准备、初始化。
- 1)验证,文件格式、元数据、字节码、符号引用验证;
- 2)准备,为类的静态变量分配内存,并将其初始化为默认值;
- 3)解析,把类中的符号引用转换为直接引用
- 初始化,为类的静态变量赋予正确的初始值。
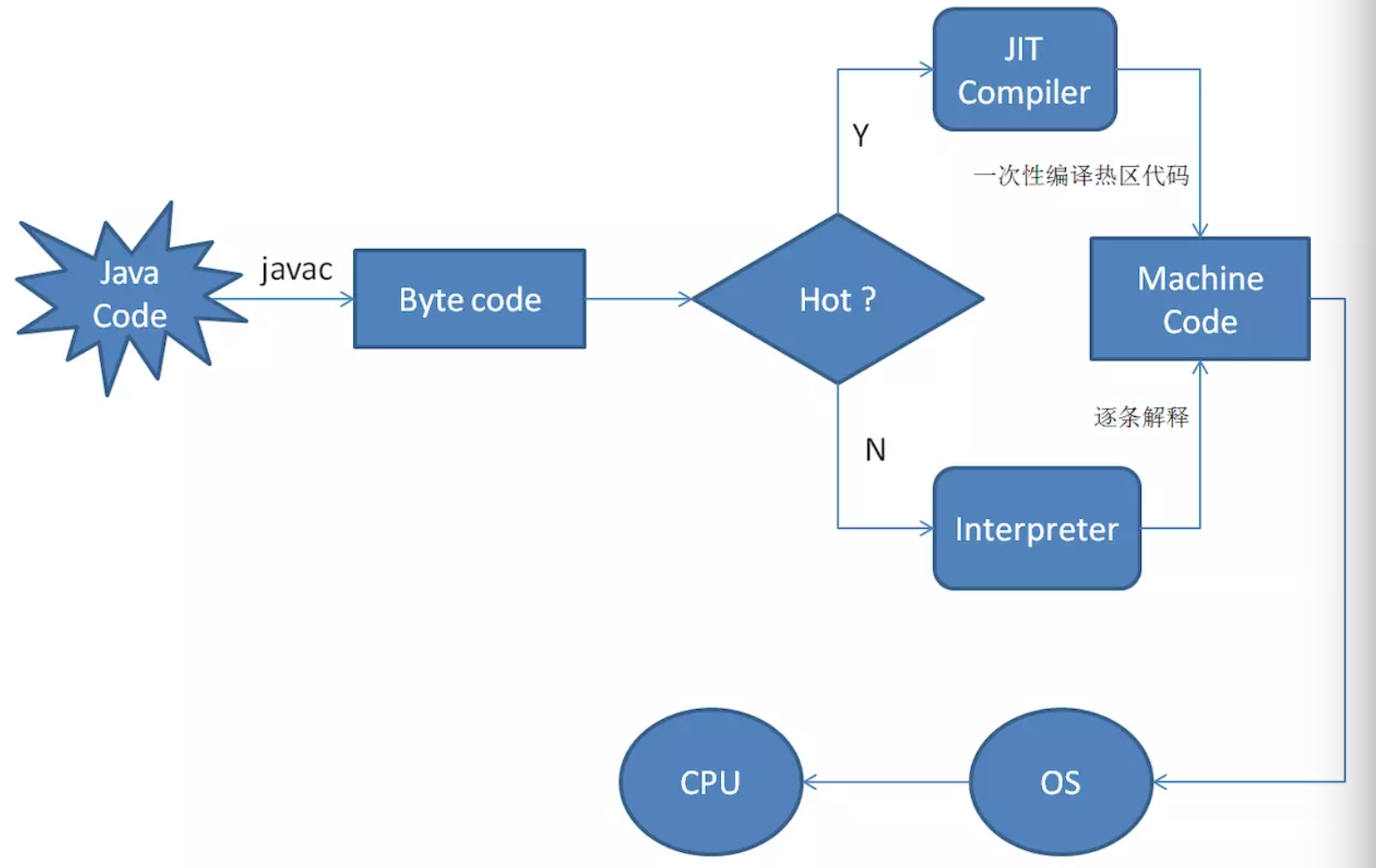
JIT即时编译器
一般我们想,JVM在加载了这些class文件以后,针对这些字节码,逐条取出,逐条执行,解析器解析。
实际上。JVM会把字节码重新编译优化,生成机器码,让CPU直接执行,这样编出来的代码效率会更高。编译也是要花时间的,JVM一般会对热点代码做编译,非热点代码直接解析就好了。
热点代码就是1 多次调用的方法 2 多次执行的循环体
使用热点探测来检测是否为热点代码,热点探测有两种方式:采样和计数器
目前HotSpot使用的是计数器的方式,它为每个方法准备了两类计数器:
- 方法调用计数器(Invocation Counter)
- 回边计数器(Back EdgeCounter)。
- 在确定虚拟机运行参数的前提下,这两个计数器都有一个确定的阈值,当计数器超过阈值溢出了,就会触发JIT编译。
回到例子
按我们程序来走,我们的PersonTest.class 文件会被AppClassLoader加载器加载到JVM中。随后发现了要使用Peron这个类,所以Person.class 文件会被APPClassLoader加载器加载到JVM中。
类加载完该干什么
JVM内存模型
堆:存放对象实例,几乎所有的对象实例都在这里分配内存
虚拟机栈:虚拟机栈描述的是Java方法执行的内存模型:每个方法被执行的时候都会同时创建一个栈帧(Stack Frame)用于存储局部变量表、操作栈、动态链接、方法出口等信息
本地方法栈:本地方法栈则是为虚拟机使用到的Native方法服务。
方法区:存储已被虚拟机加载的类元数据信息(元空间)
程序计数器:当前线程所执行的字节码的行号指示器
例子中的流程
1、通过java.exe运行PersonTest.class,随后被加载到JVM中,元空间存储着类的信息(包括类的名称、方法信息、字段信息..)。
2、然后JVM找到PersonTest的主函数入口(main),为main函数创建栈帧,开始执行main函数
3、main函数的第一条命令是Person person = new Person();就是让JVM创建一个Person对象,但是这时候方法区中没有Person类的信息,所以JVM马上加载PErson类,把Person类的类型信息放到方法区中(元空间)
4、加载完Person类之后,Java虚拟机做的第一件事情就是在堆区中为一个新的Person实例分配内存, 然后调用构造函数初始化Person实例,这个Person实例持有着指向方法区的Person类的类型信息(其中包含有方法表,java动态绑定的底层实现)的引用
5、当使用person.setName("Person");的时候,JVM根据person引用找到Person对象,然后根据Person对象持有的引用定位到方法区中Person类的类型信息的方法表,获得setName()函数的字节码的地址
6、为setName()函数创建栈帧,开始运行setName()函数
JVM之JIT
just in time
just in time 编译,也叫做运行时编译,不同于C/C++语言直接被翻译成机器指令,Java把Java的源文件翻译成了class文件,而class文件中全都是Java字节码,那么,JVM在加载了这些class文件之后,针对这些字节码,逐条取出,逐条执行,这种方法就是解释执行。
还有一种,就是把这些Java字节码重新编译优化,生成机器码,让CPU直接执行,这样编出来额代码效率会更高,通常,我们不必把所有的Java方法都编译成机器码,只需要把调用最频繁,占据CPU时间最长的方法找出来将其编译成机器码,这种调用最频繁的Java方法就是常说的热点方法。
这种在运行时按需编译的方式就是just in time
主要技术点
JIT的主要技术点,从大的框架来说,非常简单,就是申请一块既有写权限,又有执行权限的内存,然后把你要编译的Java方法,翻译成机器码,写到这块内存里,当再需要调用原来的Java方法时,就转向调用这块内存。
HotSpot 编译
当JVM执行代码时,它并不立即开始编译代码,主要有两个原因:
首先,如果这段代码本身在将来只会被执行一次,那么从本质上来看,编译就是在浪费精力,因为直接解释执行相对于编译这段代码并执行代码来说,要快很多。
当然,如果一段代码频繁的调用方法,或者是一个循环,也就是这段代码被执行多次,那么编译就非常值得了,Hot Spot VM 采用了 JIT compile 技术,将运行频率很高的字节码直接编译为机器指令执行以提高性能,所以当字节码被 JIT 编译为机器码的时候,要说它是编译执行的也可以。也就是说,运行时,部分代码可能由 JIT 翻译为目标机器指令(以 method 为翻译单位,还会保存起来,第二次执行就不用翻译了)直接执行。
第二个原因是最优化,当 JVM 执行某一方法或遍历循环的次数越多,就会更加了解代码结构,那么 JVM 在编译代码的时候就做出相应的优化。
Author: corn1ng
Link: https://corn1ng.github.io/2018/03/07/JVM/JVM举例与JIT/
License: 知识共享署名-非商业性使用 4.0 国际许可协议