Redis单线程架构与五种数据类型应用
Redis 单线程架构与五种数据类型应用
Redis 所有数据都是存放在内存中的,所以把数据放在内存中是Redis速度快的最主要原因。Redis 使用C语言实现的,执行速度相对会更快。Redis 使用了单线程架构,预防了多线程可能产生的竞争问题。
全局命令
1 | 查看所有键 |
单线程架构
Redis使用了单线程架构和I/O多路复用模型来实现高性能的内存数据库服务。
因为Redis是单线程来处理命令的, 所以一条命令从客户端达到服务端不会立刻被执行, 所有命令都会进入一个队列中, 然后逐个被执行。
为什么单线程这么快
第一, 纯内存访问, Redis将所有数据放在内存中, 内存的响应时长大约为100纳秒, 这是Redis达到每秒万级别访问的重要基础。第二, 非阻塞I/O, Redis使用epoll作为I/O多路复用技术的实现, 再加上Redis自身的事件处理模型将epoll中的连接、 读写、 关闭都转换为事件, 不在网络I/O上浪费过多的时间。第三, 单线程避免了线程切换和竞态产生的消耗。
字符串
批量操作指令MGET key1 key2 和MSET key1 v1 key2 v2 可以有效提高开发效率,没有和有的区别如图
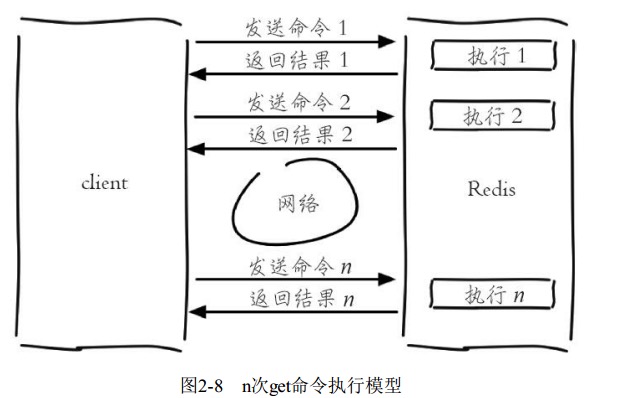
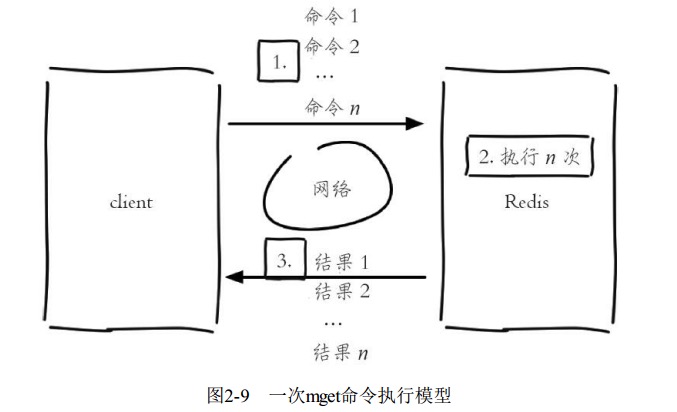
Redis可以支撑每秒数万的读写操作, 但是这指的是Redis服务端的处理能力, 对于客户端来说, 一次命令除了命令时间还是有网络时间.
字符串类型的内部编码有3种:·int: 8个字节的长整型。·embstr: 小于等于39个字节的字串。 ·raw: 大于39个字节的字符串。Redis会根据当前值的类型和长度决定使用哪种内部编码实现。
典型使用场景
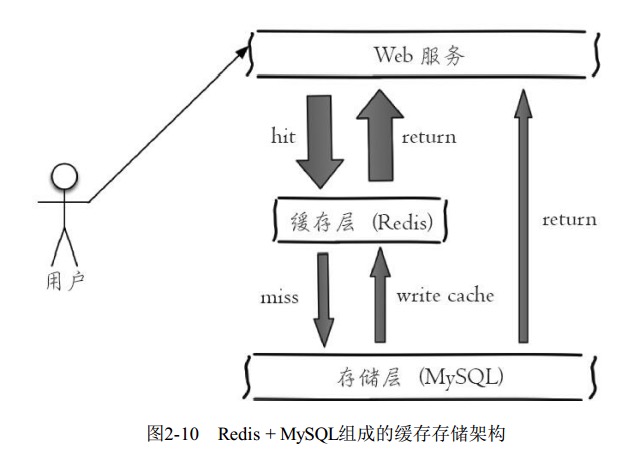
1 缓存功能
2 计数
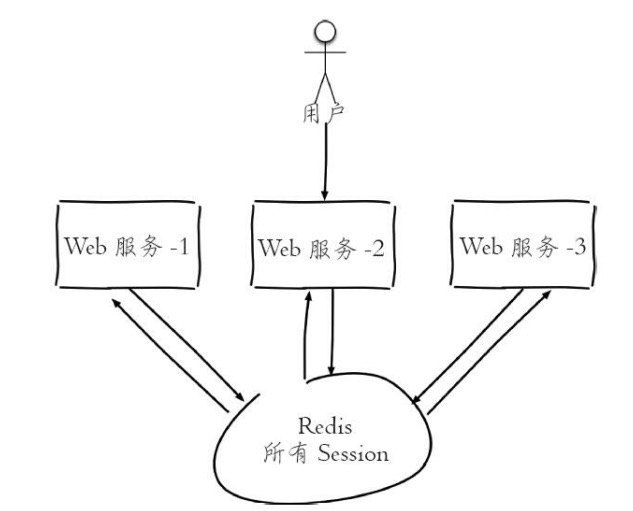
3 共享Session
哈希
哈希类型的内部编码有两种:
·ziplist( 压缩列表) : 当哈希类型元素个数小于hash-max-ziplist-entries配置( 默认512个) 、 同时所有值都小于hash-max-ziplist-value配置( 默认64字节) 时, Redis会使用ziplist作为哈希的内部实现, ziplist使用更加紧凑的结构实现多个元素的连续存储, 所以在节省内存方面比hashtable更加优秀。
·hashtable( 哈希表) : 当哈希类型无法满足ziplist的条件时, Redis会使用hashtable作为哈希的内部实现, 因为此时ziplist的读写效率会下降, 而hashtable的读写时间复杂度为O( 1)
使用场景
用哈希表缓存用户信息,将每个用户的ID定义为键的后缀,多对field-value 对应每个用户的属性。
列表
列表是一种比较灵活的数据结构, 它可以充当栈和队列的角色, 在实际开发上有很多应用场景。
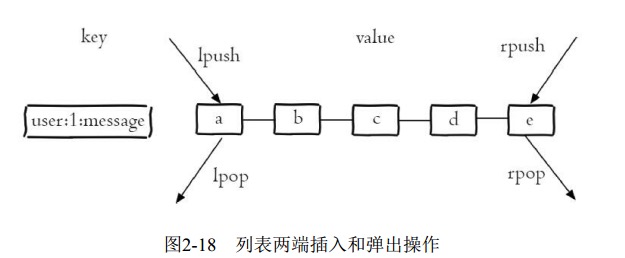
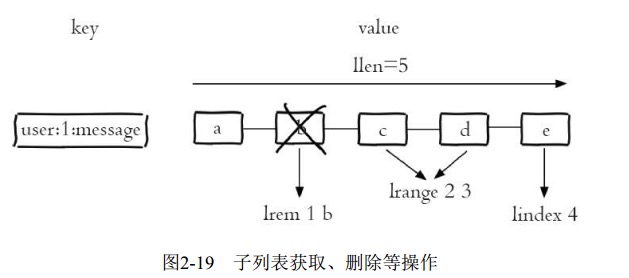
列表类型有两个特点: 第一、 列表中的元素是有序的, 这就意味着可以通过索引下标获取某个元素或者某个范围内的元素列表.第二、 列表中的元素可以是重复的.
列表类型的内部编码有两种。·ziplist( 压缩列表) : 当列表的元素个数小于list-max-ziplist-entries配置( 默认512个) , 同时列表中每个元素的值都小于list-max-ziplist-value配置时( 默认64字节) , Redis会选用ziplist来作为列表的内部实现来减少内存的使用。·linkedlist( 链表) : 当列表类型无法满足ziplist的条件时, Redis会使用linkedlist作为列表的内部实现。
使用场景
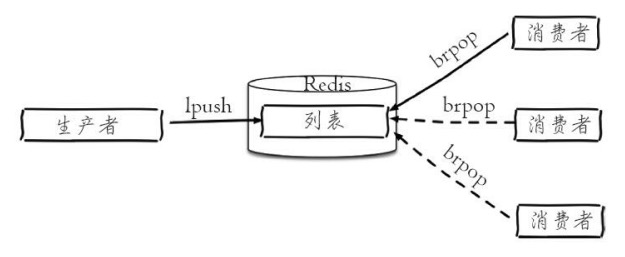
1 消息队列 Redis的lpush+brpop命令组合即可实现阻塞队列, 生产者客户端使用lrpush从列表左侧插入元素, 多个消费者客户端使用brpop命令阻塞式的“抢”列表尾部的元素, 多个客户端保证了消费的负载均衡和高可用性
集合
集合中不允许有重复元素, 并且集合中的元素是无序的, 不能通过索引下标获取元素。
集合类型的内部编码有两种:·intset( 整数集合) : 当集合中的元素都是整数且元素个数小于set-maxintset-entries配置( 默认512个) 时, Redis会选用intset来作为集合的内部实现, 从而减少内存的使用。·hashtable( 哈希表) : 当集合类型无法满足intset的条件时, Redis会使用hashtable作为集合的内部实现。
使用场景
集合类型比较典型的使用场景是标签( tag)
有序集合
有序集合中的元素可以排序。 但是它和列表使用索引下标作为排序依据不同的是, 它给每个元素设置一个分数( score) 作为排序的依据。
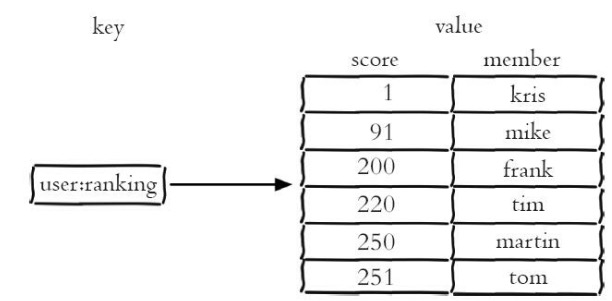
该有序集合包含kris、 mike、 frank、 tim、 martin、 tom,它们的分数分别是1、 91、 200、 220、 250、 251, 有序集合提供了获取指定分数和元素范围查询、 计算成员排名等功能.元素不能重复,分数可以重复。
有序集合类型的内部编码有两种:·ziplist( 压缩列表) : 当有序集合的元素个数小于zset-max-ziplistentries配置( 默认128个) , 同时每个元素的值都小于zset-max-ziplist-value配置( 默认64字节) 时, Redis会用ziplist来作为有序集合的内部实现, ziplist可以有效减少内存的使用。·skiplist( 跳跃表) : 当ziplist条件不满足时, 有序集合会使用skiplist作为内部实现, 因为此时ziplist的读写效率会下降。
Author: corn1ng
Link: https://corn1ng.github.io/2018/01/25/Redis 单线程架构与五种数据类型应用/
License: 知识共享署名-非商业性使用 4.0 国际许可协议