可扩展的MYSQL
Contents
可扩展的MYSQL
容量是一个和可拓展性相关的概念,系统容量表示在一定时间内能够完成的工作量,容量必须是可以有效利用的,系统的最大吞吐量不等同于容量。从较高层次来看,可拓展性就是能够通过增加资源来提升容量的能力。
可拓展性的定义: 可拓展性是当增加资源以处理负载和增加容量时系统能够获得的投资产出率.
扩展MySQL
如果将应用所有的数据简单的放到单个MySQL服务器实例上,则无法很好的扩展,迟早会遇到性能瓶颈.传统的解决方法是购买更多强悍的机器,也就是常说的”垂直扩展”或者”向上扩展”,另外一个与之相反的方法是将任务分配到多台计算机上,通常称为”水平扩展”或者”向外扩展”,另外,大部分应用还会有一些很少或者从来不需要的数据,这些数据可以被清理或者归档,将这个方案称为”向内扩展”.
通常在无法满足增加的负载时会考虑可扩展性,具体表现为工作负载从CPU密集型变成IO密集型,并发查询的竞争,以及不断增大的延迟.
规划可扩展性
人们都长只有在无法满足增加的负载时才会考虑到可扩展性,具体表现为工作负载从CPU密集型变成IO密集型,并发查询的竞争,以及不断增加的延迟。
向上扩展
向上扩展意味着购买更多的硬件,对许多应用来说这是唯一需要做的事情,这种策略有很多好处,比如更容易维护和开发,能显著节约开销
向上扩展的策略可能能够持续一段时间,实际上很多应用是达不到天花板的,但是如果应用十分庞大,向上扩展可能就没有办法了,
向外扩展(垂直拆分和水平拆分)
垂直拆分就是根据业务拆到不同的库中,水平拆分可以分到不同的库中,也可以分到不同的表中。
可以把向外扩展策略划分为三个部分,复制,拆分,以及数据分片。
最简单最常见的向外扩展的方法是通过复制将数据分发到多个服务器上,然后将备库用于读查询,这种技术对于以读为主的应用很有效,但是缺点也很明显,例如重复缓存,
另外一个比较常见的向外扩展方法是将工作负载分布到多个节点,具体如果分布工作负载是一个复杂的话题, 在MySQL架构中,一个节点就是一个功能部件,如果没有规划冗余和高可用性,那么一个节点可能就是一个服务器,如果设计的是能够故障转移的冗余系统,那么一个节点可能是1)一个主主复制的双机结构,2)一个主库和多个备库3)一个主动服务器,并使用分布式复制块设备作为备用服务器4)一个基于存储区域网络的集群
大多数情况下,一个节点内的所有服务器应该拥有相同的数据,
按功能拆分
按功能拆分,或者按职责拆,意味着不同的节点执行不同的任务,例如一个网站,各个部分无需共享数据,那么可以按照网站的功能区域进行划分,
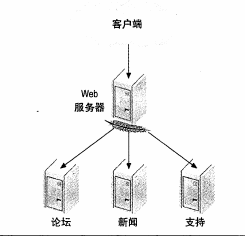
如果应用很大,每个功能区域还可以拥有其专用的web服务器.但是一旦采用了按功能划分,以后就不好进行更具扩展性的设计了.
另一个可能的按功能划分方法是对单个服务器的数据进行划分,并确保划分的表集合之间不会执行关联操作。
归根结底,还是不能通过功能划分来无限地进行拓展,因为如果一个功能区域被捆绑到单个Mysql 节点,就只能进行垂直扩展。
数据分片
在目前扩展大型MySQL应用的方案中,数据分片是最通用,最成功的方法,它把数据分割成一小片,或者说一块,然后存储到不同的节点中,
数据分片在和某些类型的按功能划分联合使用时非常有用,大多数分片系统也有一些全局的数据不会被分片.全局数据一般存储在单个节点上. 事实上,大部分应用只会对需要的数据做分片,—通常是那些会增长的非常庞大的数据,
大型应用可能有多个逻辑数据集,并且处理方式也可以各不相同,可以将他们存储到不同的服务器组上,但这并不是必需的。还可以以多种方式对数据进行分片,这取决于如何使用他们。
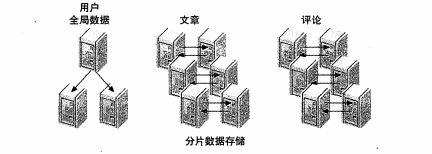
采用分片的应用常会有一个数据库访问抽象层,用以降低应用和分片数据存储之间通信的复杂度,但无法完全隐藏分片,因为相比数据存储,应用通常更了解跟查询相关的一些信息。
- 选择分区键
数据分片最大的挑战是查找和获取数据,如何查询数据取决于如何进行分片,有很多方法,其中有一些方法会比另外一些更好。我们的目标是对那些最重要并且频繁查询的数据减少分片。这其中最重要的是如何为数据选择一个或者多个分区键,分区键决定了每一行分配到哪一个分片中,如果知道一个对象的分区键,就可以回答如下两个问题:应该在哪里存储数据,应该从哪里取得希望取得的数据。一个好的分区键常常是数据库中一个非常重要的实体的主键,这些键决定了分片单元,选择分区键的时候,尽可能选择那些能够避免跨分片查询的,但同时也要让分片足够小,以免过大的数据片导致问题。
通过多实例扩展
不要在一个性能很强的服务器上只运行一个服务器实例,我们还有别的选择,可以让数据分片足够小,以使每台机器上都能放置多个分片,每台服务器上运行多个实例,然后划分服务器的硬件资源,将其分配给每个实例.
通过集群扩展
理想的扩展方案是单一逻辑数据库能够存储尽可能多的数据,处理尽可能多的查询,并且如期望的那样增长,随着云计算的流行,自动扩展-根据负载或者数据大小动态地在集群中增加/移除服务器越来越多.
向内扩展
处理不断增加的数据和负载最简单的方法是对不再需要的数据进行归档和清理,这种操作可能带来显著的成效,具体取决于工作负载和数据特性,这种做法并不用来代替其他策略,但是可以作为争取时间的短期策略,也可以作为处理大数据量的长期计划之一.
负载均衡
首先,集群和分布式的区别
分布式:一个业务分拆多个子业务,部署在不同的服务器上
集群:同一个业务,部署在多个服务器上
负载均衡的思路很简单,在一个服务器集群中尽可能的平均负载量,通常的做法是在服务器前端设置一个负载均衡器(一般是专门的硬件设备),然后负载均衡器将请求的连接路由到最空闲的可用服务器,下图是一个大型网站的负载均衡设置,其中一个负载均衡器用于http流量,另一个用于MySQL访问
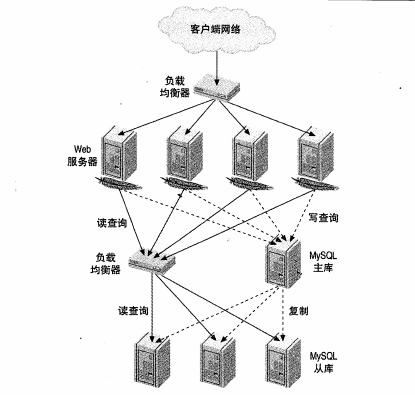
负载均衡的主要目的有可扩展性,高效性,可用性,透明性,一致性.
在与MySQL相关的领域中,负载均衡通常与数据分片及复制紧密相关.可以把负载均衡和高可用性结合在一起,部署到应用的任一层次上.
应用与MySQL直接相连
复制上的读写分离
MySQL复制产生了多个数据副本,由于备库复制是异步的,因此难点在于如何处理备库上的脏数据,应该将备库用作只读的,而主库可以同时处理读和写查询.
比较常见的读写分离方法如下:
- 基于查询分离:最简单的分离方法是将所有不能容忍脏数据的读和写查询分配到主库服务器上,其他的读查询分配到备库或被动服务器上,
- 基于脏数据分离,这是对基于查询分离方法的小改进,需要做一些额外的工作,让应用检查复制延迟,以确定备库数据是否太旧,许多报表类应用都使用这个策略,只需要晚上加载的数据复制到备库疾苦,它们并不关心是不是100%跟上了主库。
- 基于会话分离 判断用户自己是否修改了数据,用户不需要看到其他用户的最新数据,但是需要看到自己的更新,可以在会话层设置一个标记位,表明做了更新,就将该用户的查询在一段时间内总是指向主库,这是十分推荐的策略,因为它是在简单和有效性之间的一种很好的妥协。
大多数读写分离解决方案都需要监控复制延迟来决策读查询的分配,不管是通过复制或负载均衡器,或是一个中间系统。
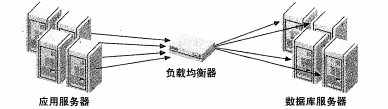
引入中间件
许多负载均衡方案都会引入一个中间件,作为网络通信的代理,它一边接受所有的通信请求,另一边将这些请求派发到指定的服务器上,然后把执行结果发送回请求的机器上.中间件可以是硬件设备或是软件,
Author: corn1ng
Link: https://corn1ng.github.io/2018/01/03/老板MYSQL/可扩展的MYSQL/
License: 知识共享署名-非商业性使用 4.0 国际许可协议