Java集合
Contents
集合框架体系如图所示:
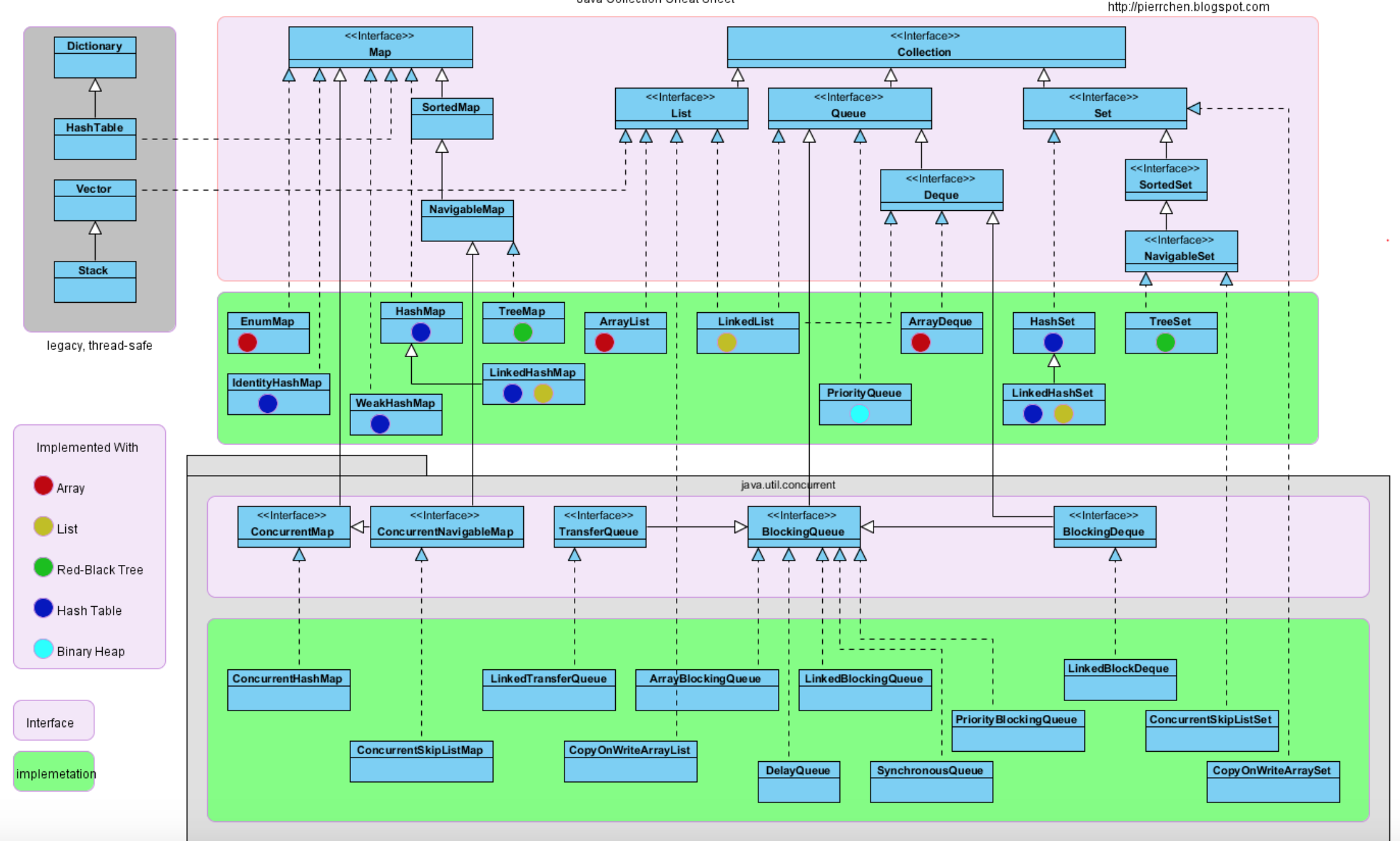
集合框架中的接口
- Collection 接口
Collection 是最基本的集合接口,一个 Collection 代表一组 Object,即 Collection 的元素, Java不提供直接继承自Collection的类,只提供继承于的子接口(如List和set)。
- List 接口
List接口是一个有序的 Collection,使用此接口能够精确的控制每个元素插入的位置,能够通过索引(元素在List中位置,类似于数组的下标)来访问List中的元素,第一个元素的索引为 0,而且允许有相同的元素。
- Set 接口
Set 具有与 Collection 完全一样的接口,只是行为上不同,Set 不保存重复的元素。
- SortedSet
继承自Set保存有序的集合
- Map
将唯一的键映射到值
- Map.Entry
描述在Map中的一个元素(键值对),是一个Map的内部类
- SortedMap
继承于Map,使Key 保持在升序排列.
集合类中的基本接口是 collection 接口 有两个基本方法
1 | public interface Collection<E> |
list 是collection 的子接口定义如下1
public interface List<E> extends Collection<E>
list 接口扩充了许多其他方法,1
2
3public void add(int index,E element);//指定位置添加元素。
E get(int index); // 返回指定位置的元素。
public int indexof(E element);//查找指定元素的位置。
iterator()方法用于返回一个实现了Iterator 接口的对象。可以使用这个对象依次访问集合中的元素。
Iterator接口包含三个方法1
2
3
4
5
6public interface Iterator<E>
{
E next();
boolean hasNext;
void remove();
}
在调用next之前调用hasNext方法。在集合中,查找一个元素唯一的方法就是调用next,在执行查找操作的同时,迭代器的位置向前移动。因此,应该将Java迭代器认为是位于两个元素之间,当调用next时,迭代器就越过下一个元素,并返回刚刚越过的元素的引用。
具体的集合
除了以map结尾的类之外,其他类都实现了collection接口,map结尾的实现了map接口。
一个例子
LinkedList(双向链表实现)
1 | List<String> list =new LinkedList<String>(); |
链表是一个有序集合,由于迭代器是描述集合中位置的,所以这种依赖于位置的add方法将由迭代器负责,只有对自然有序的集合使用迭代器添加元素才有实际意义。因此iterator接口中没有add方法,在子接口ListIterator中包含了add方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15iterator ListIterator<E> extends Iterator<E>
{
void add(E elements);
// 还有两个方法用来反向遍历链表。
E previous();
boolean hasPrevious();
}
List<String> staff = new LinkedList<>();
staff.add("A");
staff.add("B");
staff.add("C");
ListIterator<String> it = staff.listIterator();
it.next();
it.add("J"); //AJBC
set() 方法用一个新元素取代调用next或者previous方法返回的上个元素。例如下面面代码用新值取代链表第一个元素。
1 | List<String> list = new LinkedList<String>(); |
ArrayList
arraylist 封装了一个动态再分配的对象数组。
ArrayList底层以数组实现,允许重复,默认第一次插入元素时创建数组的大小为10,超出限制时会增加50%的容量,每次扩容都底层采用System.arrayCopy()复制到新的数组,初始化时最好能给出数组大小的预估值。
散列集
散列表为每个对象计算一个整数,成为散列码 Java中,散列表用链表数组实现,每个列表称为桶。
树集
树集是一个有序集合,可以以任意顺序将元素插入到集合中,在对集合进行遍历时,每个值将自动的按照排序后的顺序呈现,
映射表
映射表的两个实现,HashMap,TreeMap,两个类都实现了Map接口。
散列映射表对键进行散列,树映射表用键的整体顺序对元素进行排列,并将其组织成搜索树。 散列或者比较函数都只能作用于键,与键关联的值不能进行散列或者比较。1
2
3Map<String,Employee> staff = new HashMap<>();
Emplloyee harry = new Employee("H");
staff.put("123",harry);
要想检索一个对象,必须提供一个键1
2String s = "123";
e = staff.get(s);
如果在映射表中没有给定键对应的信息,get将返回NUll。
1 | 下列方法返回三个视图。 |
1 | //枚举映射表中所有的键: |
集合框架
框架是一个类的集,奠定了创建高级功能的基础。
一个例子
1 | Map<String,String> map =new HashMap<>(); |
输出为
1 | [1=one, 2=one, 3=three, 4=four, 5=five, 6=six] |
先定义一个hashMap,加了八个元素,map.set的意思是把map变成set,且set里的元素类型都是满足Map.Entry<String,String> 接口的,然后声明一个迭代器,进行迭代输出,打印出每一个元素。
Map.Entry<String,String> 是一个Map内部定义的接口,专门用来保存key-value的内容,简单说就是Map中的每一个元素(每一个键值对)都是实现了Map.Entry<>接口的。
Iterator 和ListIterator 之间有什么区别
- 我们可以使用Iterator来遍历Set和List集合,而ListIterator只能遍历List。
- Iterator只可以向前遍历,而LIstIterator可以双向遍历。
- ListIterator从Iterator接口继承,然后添加了一些额外的功能,比如添加一个元素、替换一个元素、获取前面或后面元素的索引位置。
HashMap 和HashTable 有何不同
(1)HashMap允许key和value为null,而HashTable不允许。
(2)HashTable是同步的,而HashMap不是。所以HashMap适合单线程环境,HashTable适合多线程环境。
(3)在Java1.4中引入了LinkedHashMap,HashMap的一个子类,假如你想要遍历顺序,你很容易从HashMap转向LinkedHashMap,但是HashTable不是这样的,它的顺序是不可预知的。
(4)HashMap提供对key的Set进行遍历,因此它是fail-fast的,但HashTable提供对key的Enumeration进行遍历,它不支持fail-fast。
(5)HashTable被认为是个遗留的类,如果你寻求在迭代的时候修改Map,你应该使用CocurrentHashMap。