B 树与B+ 树
Contents
B 树
数据库结构使用树的结构索引,从算法逻辑上看,二叉查找树的查找速度和比较次数都是最小的。数据库的索引存储在磁盘上,当数据量比较大的时候,索引的大小可能有几个G 甚至更多。
当我们利用索引查询的时候,不可能把整个索引加载到内存,能做的只有逐一加载每一个磁盘页,磁盘页对应索引树的节点。
当利用二叉查找树时,每一层都是进行一次IO操作(即把对应的索引装入内存),因此最坏的情况下,磁盘的IO次数就等于索引树的高度。
为了减少IO次数,就需要把层数降低,也就是B-树
B树是一种多路平衡查找树,
m阶b树具有以下的特征。
1 | 每个结点至多拥有m棵子树; |
可以知道,b树在查询中的比较次数其实不比二叉查找树少,尤其当单一节点中元素数量很多时,但是相比磁盘IO的速度,内存中的比较耗时几乎可以忽略,所以只要树足够低,IO次数就足够少,就可以提升性能。
b树主要应用于文件系统以及部分数据库索引(MongoDB)
B + 树
B+ 树是B 树的一种变体,比B树的查询性能更高。
1 | 1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。 |
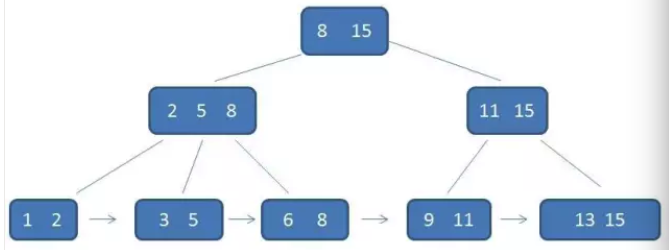
B+ 树中每个父节点的元素都出现在子节点中,是子节点的最大(最小)元素。根节点的最大元素也就等同于整个B+树的最大元素,以后无论插入删除多少元素,始终要保持最大元素在根节点中。由于父节点的元素出现在叶子节点中,因此所有的叶子节点包括了所有的信息。并且每一个叶子节点都带有一个指向下一个节点的指针,形成了一个有序链表。
在B树种,无论父节点还是子节点都带有数据,在b+ 树中,只有叶子节点带有数据,中间节点仅仅是索引,没有任何数据。
需要补充的是,在数据库的聚集索引(Clustered Index)中,叶子节点直接包含卫星数据。在非聚集索引(NonClustered Index)中,叶子节点带有指向卫星数据的指针。
B+树的好处主要体现在查询性能上,单点查询时,由于B+树中间节点没有数据,所有同样的磁盘页可以容纳更多的节点,也就是说,在数据量相同的情况下,b+ 树的结构比b树更加矮胖,IO次数也就更少。B+ 树的查询必须查到叶子节点,B树查询到匹配元素即可,所以B树查询性能不稳定。范围查询时,B 树只能中序遍历,而B+树只需要在链表中做遍历即可。所以B+ 树范围查询更加方便。
综合起来,B+ 树IO 次数少,查询性能稳定,范围查询更加方便。
m阶b+树和m阶B树的区别
- 所有叶子节点包含全部关键字信息,及指向含有这些关键字记录的指针,且叶子节点中关键字进行有序链接
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
B+树比B树更适合操作系统的文件索引和数据库索引的原因:
- B+树的磁盘读写代价更低,B+树的内部节点没有指向关键字具体信息的指针,因此内部节点相对B树更小。如果把所有同一内部节点的关键字放在同一块磁盘中,盘块所能容纳的关键字数量也就越多,一次性读入内存中的需要查找的关键字也就越多,相对IO读写次数降低
- B+树的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
总结
- B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
- B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点 中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
Author: corn1ng
Link: https://corn1ng.github.io/2017/10/10/B 树与B+ 树/
License: 知识共享署名-非商业性使用 4.0 国际许可协议